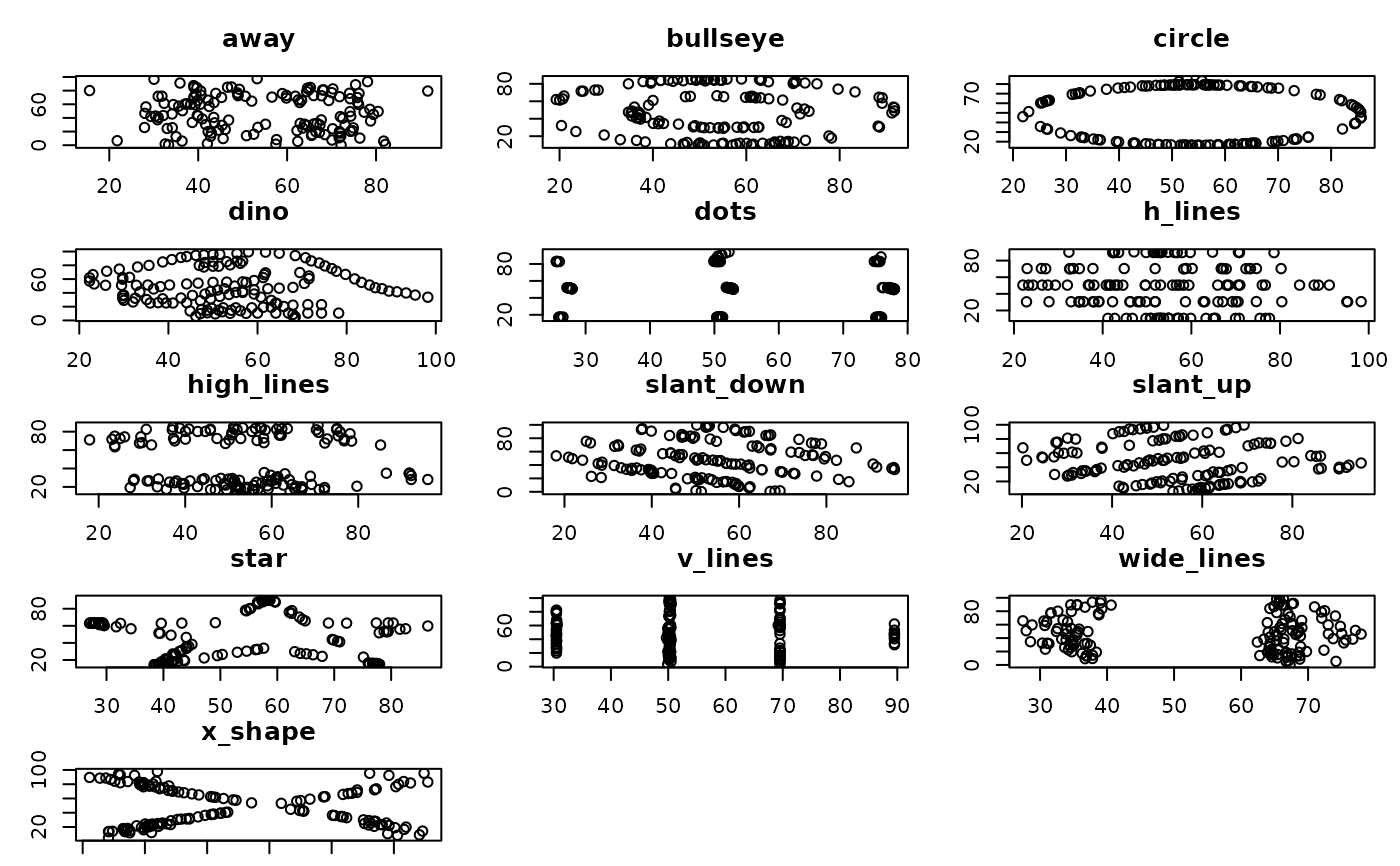
A dataset demonstrating the utility of visualization. These 12 datasets are equal in standard measures: mean, standard deviation, and Pearson's correlation.
Format
A data frame with 142 rows and 26 variables:
away_x: x-values for the
awaydatasetaway_y: y-values for the
awaydatasetbullseye_x: x-values for the
bullseyedatasetbullseye_y: y-values for the
bullseyedatasetcircle_x: x-values for the
circledatasetcircle_y: y-values for the
circledatasetdino_x: x-values for
dinosaurdataset!dino_y: y-values for
dinosaurdataset!dots_x: x-values for the
dotsdatasetdots_y: y-values for the
dotsdataseth_lines_x: x-values for the
h_linesdataseth_lines_y: y-values for the
h_linesdatasethigh_lines_x: x-values for the
high_linesdatasethigh_lines_y: y-values for the
high_linesdatasetslant_down_x: x-values for the
slant_downdatasetslant_down_y: y-values for the
slant_downdatasetslant_up_x: x-values for the
slant_updatasetslant_up_y: y-values for the
slant_updatasetstar_x: x-values for the
stardatasetstar_y: y-values for the
stardatasetv_lines_x: x-values for the
v_linesdatasetv_lines_y: y-values for the
v_linesdatasetwide_lines_x: x-values for the
wide_linesdatasetwide_lines_y: y-values for the
wide_linesdatasetx_shape_x: x-values for the
x_shapedatasetx_shape_y: y-values for the
x_shapedataset
References
Matejka, J., & Fitzmaurice, G. (2017). Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing. CHI 2017 Conference proceedings: ACM SIGCHI Conference on Human Factors in Computing Systems. Retrieved from https://www.autodeskresearch.com/publications/samestats.
Examples
# Save current settings
state <- par("mar", "mfrow")
# Base R Plots
par(mfrow = c(5, 3), mar=c(1, 3, 3, 1))
nms <- names(datasaurus_dozen_wide)
for (i in seq(1, 25, by = 2)){
nm <- substr(nms[i], 1, nchar(nms[i]) - 2)
plot(datasaurus_dozen_wide[[nms[i]]],
datasaurus_dozen_wide[[nms[i+1]]],
xlab = "", ylab = "", main = nm)
}
#reset settings
par(state)