How to go about interpreting regression cofficients
Following my post about logistic regressions, Ryan got in touch about one bit of building logistic regressions models that I didn’t cover in much detail – interpreting regression coefficients. This post will hopefully help Ryan (and others) out.
This was so helpful. Thank you! I'd love to see more about interpreting the glm coefficients.
— Ryan (@RyanEs) April 21, 2017
What is a coefficient?
Coefficients are what a line of best fit model produces. A line of best fit (aka regression) model usually consist of an intercept (where the line starts) and the gradients (or slope) for the line for one or more variables.
When we perform a linear regression in R, it’ll output the model and the coefficients.
Call:
lm(formula = Sepal.Width ~ Sepal.Length + Petal.Width + Species, data = iris)
Coefficients:
(Intercept) Sepal.Length
1.9309 0.2730
Petal.Width Speciesversicolor
0.5307 -1.4850
Speciesvirginica
-1.8305
Each value represents the straight line relationship between each variable and the predicted variable. For every one unit of change for each input variable, the coefficient tells us how much we should change our predicted variable.
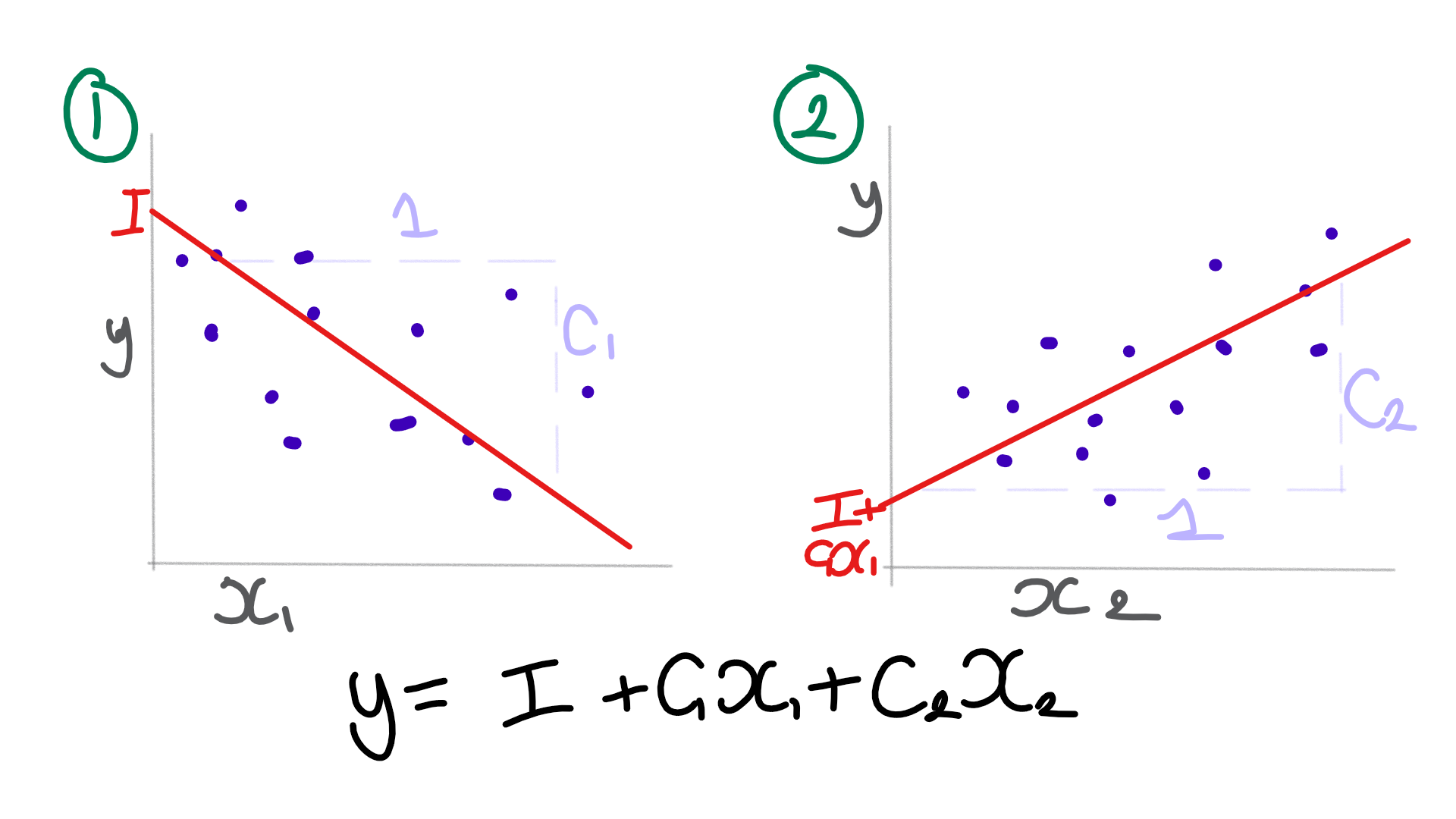
Interpreting coefficients
When we read the list of coefficients, here is how we interpret them:
- The intercept is the starting point – so if you knew no other information it would be the best guess.
- Each coefficient multiplies the corresponding column to refine the prediction from the estimate. It tells us how much one unit in each column shifts the prediction.
- When you use a categorical variable, in R the intercept represents the default position for a given value in the categorical column. Every other value then gets a modifier to the base prediction.
So for our linear regression of our iris data, we can say that:
- For setosas, with no other information, we expect a sepal width of 1.93cm
- For versicolors, with no other information, we expect a sepal width of 0.54cm (1.93cm + -1.49cm)
- For virginicas, with no other information, we expect a sepal width of 0.10cm (1.93cm + -1.83cm)
- For every 1cm of sepal length, we increase our estimated sepal width by 0.27cm
- For every 1cm of petal width, we increase our estimated sepal width by 0.53cm
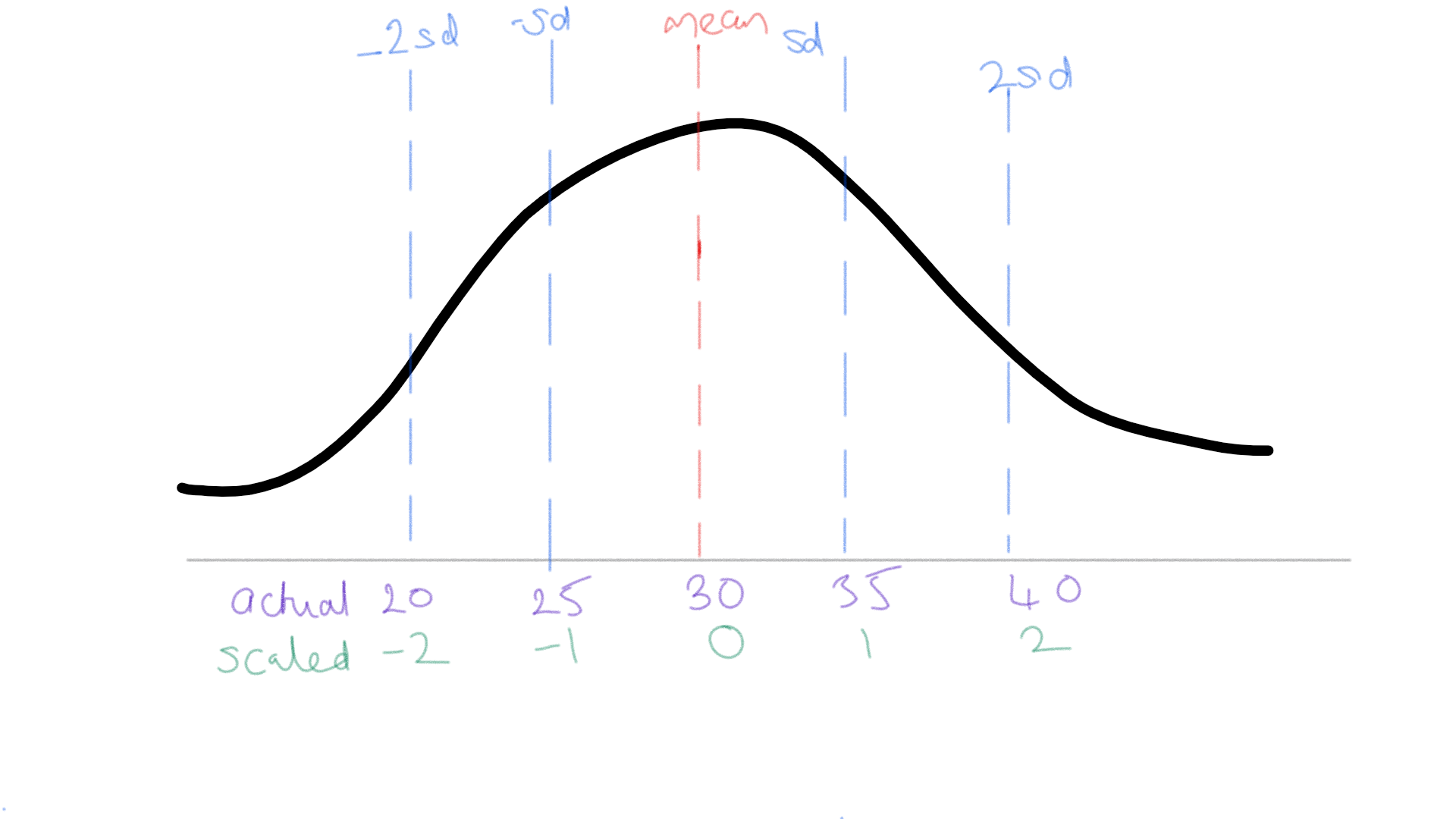
Scaled variables
When we use z-score scaling, the coefficients represent the impact of one standard deviation’s worth of change. As such, to determine the impact of one unit of change in the underlying variable you would divide the coefficient by the standard deviation of the underlying variable.
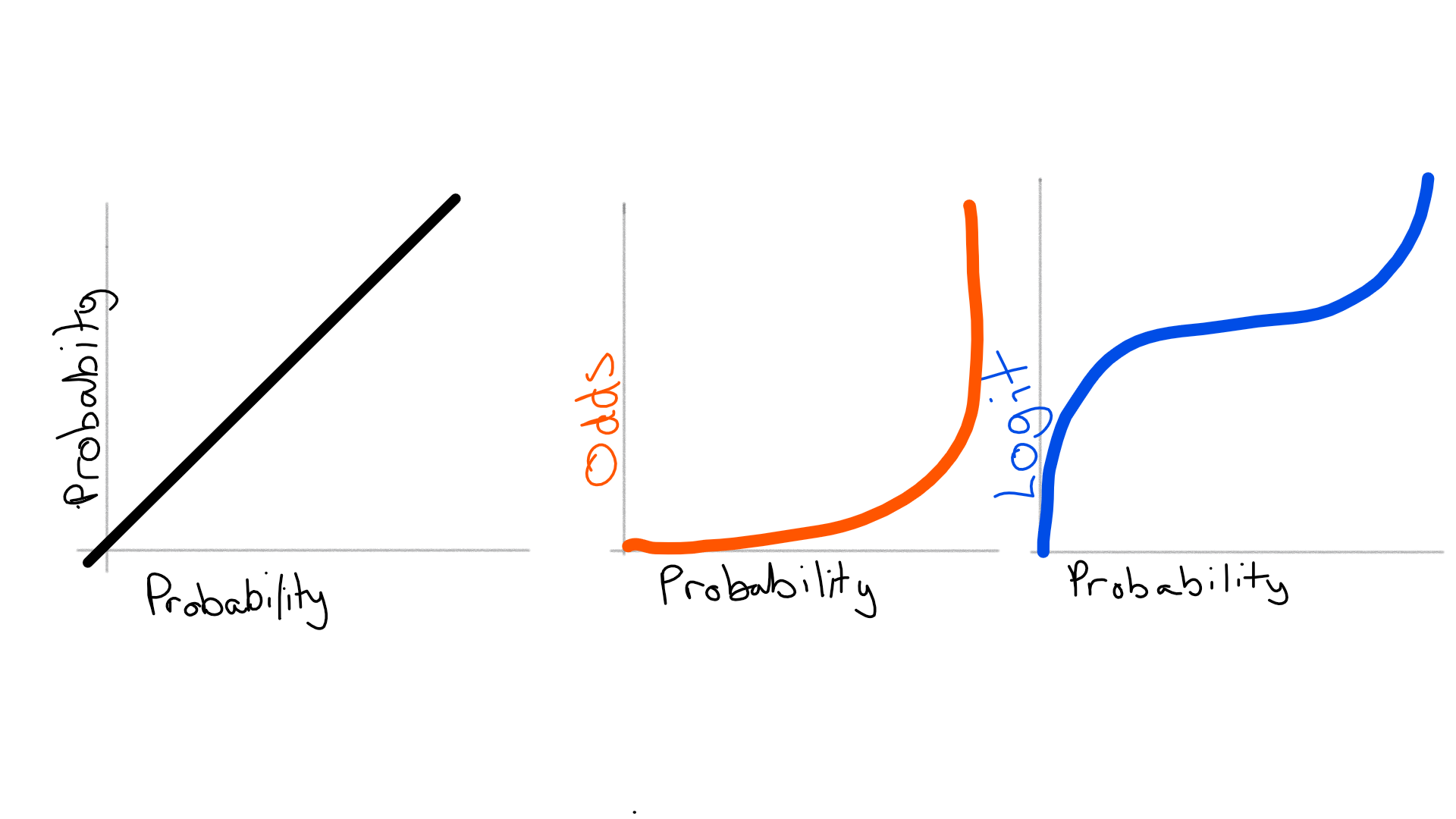
Logistic regression
With a logistic regression, the outcome value is the logit, or log of the odds of an event happening. Any sum of values from the regression that is greater than 0 would represent classifying it as the thing we’re trying to predict. Interpreting logits is rather more complicated because we’re dealing with logarithms and odds.
Not all of the maths will be explained here. Check out Win-vectors derivation of logistic regression for a more proof-oriented read.
How do odds work?
An odds ratio is the probability of something happening versus it not happening i.e. $latex frac{p}{1-p}$
Odds can be expressed in nicer ratios, e.g. 2:1, where the sum of the two numbers represents the denominator for working out each probability. So it becomes (2⁄3):(1⁄3) and the odds would be $latex frac{frac{2}{3}}{frac{1}{3}}$ or 2.
You convert from an odds ratio back to a probability by doing $latex frac{o}{1+o}$.
Confirm it in R:
p=0.5; o=1; all.equal(p/(1-p), o); all.equal(o/(1+o), p)
To combine two odds we multiply them. $latex frac{p_1}{1-p_1} frac{p_2}{1-p_2}$
Confirm it in R:
p=0.875; oA=2; oB=4; oO=oA*oB; all.equal(p/(1-p), oO, (oA*oB)/(1+(oA*oB)))
Why do we do the logarithm?
We do the logarithm in big part because it gives us a $latex [-infty,+infty]$ value to predict, but we can only do it because of a fundamental property of logarithms, namely, that adding to logarithms is equivalent to taking the logarithm of the multiplied values i.e. $latex ln(a) + ln(b) = ln(a*b)$
Confirm it in R:
all.equal( log(2) + log(3) , log(2*3) )
This means that when we sum the logit components in a logistic regression, we’re effectively taking the log of all the multiplied odds values.
So how do I understand the impact?
Firstly, it’s a logarithmic scale where a logit of 0 is 1:1 odds.
| logit | odds | oddsratio |
|---|---|---|
| -1.6094379 | 0.2 | 1:5 |
| -0.9162907 | 0.4 | 2:5 |
| -0.5108256 | 0.6 | 3:5 |
| -0.2231436 | 0.8 | 4:5 |
| 0.0000000 | 1.0 | 5:5 |
| 0.1823216 | 1.2 | 6:5 |
| 0.3364722 | 1.4 | 7:5 |
| 0.4700036 | 1.6 | 8:5 |
| 0.5877867 | 1.8 | 9:5 |
| 0.6931472 | 2.0 | 10:5 |
If I had a coefficient of 0.69 for a variable in my model, it would be equivalent to every unit of change in that variable doubling the likelihood from the other variables.
If I had a coefficient of -1.6 for a variable in my model, it would be equivalent to every unit of change in that variable reducing the likelihood from the other variables by 5⁄6.
I made an R package, optiRum, that has helper functions for translating between probabilities, odds, and logits. Hopefully, it’ll help you out when needing to move between different measures and making them interpretable.
Wrap up
Hopefully, this has helped you become more comfortable interpreting regression coefficients. If you’d like to learn more about working with logistic regressions, check out my recent logistic regressions (in R) post. If you have any questions or comments, please add them below!