Harmonizing and emojifying our GitHub issue trackers
A part of Locke Data’s mission is sharing R knowledge and tooling with the world for free. If you have a look at our GitHub account, you’ll see we’ve pinned six of our package repos. Furthermore, to make it easier to find all the R stuff we’ve packaged up, we’ve added an “r-package” repo topic to all packages: find them all via this URL. Adding such repo topics isn’t the only harmonization effort we’ve done to make it easier to maintain and promote our packages suite. In this post, at the request of Irene Steves, we shall explain why and how we semi-automatically harmonized and emojified our issue trackers with the help of GitHub’s V3 API and of the gh package!
Emojify what? A short intro to GitHub issue tracker organization
If you’re a bit familiar with software development on GitHub, either because you develop your own packages or sometimes browse the repos of other packages, you’ll know each repository has an issue tracker. That’s the place where bugs and feature requests are gathered. Both repo members and external contributors can add stuff to the list! Often, the issue tracker is your personal to-do list because no one else cares yet, and you can get righteously very excited over any new issue!
Yaaayy!! I built a thing and somebody is using it :)
— El esposo de Daniela 💉💉💉 (@g3rv4) July 10, 2018
I guess this is what popular OSS library authors feel when they get an issue, right?https://t.co/2WyqcOkElW
But as your repo gets a bit more popular, or as you yourself take notes of a lot of stuff, your to-do list gets very long and hard to make sense of! GitHub provides tool for organizing it. Of particular interest are milestones that are collections of issues corresponding to say how you imagine each future release to be, and labels that indicate what each issue is about; so you can have issues related to docs. Labels can also indicate the level needed to resolve an issue, and whether you’d welcome external contributors, cf this GitHub article. Labels are great, for instance you can decide to work on only docs on one day and filter issues that are related to that.
Why harmonizing sets of issue labels over an organization?
As mentioned above, Locke Data maintains a few packages now. Each of them used to have its own set of issue labels. We decided to make them all similar for two reasons. First, it’s nice to speak the same language over different projects within our GitHub organization, making it easier to transition from one repo to the other. Then, we wanted to be able to eventually make use of tools such as Jim Hester’s tidyversedashboard package, and thought the issue tab would be handier if having similar labels.
Therefore, we set off to decide on a set of issue labels!
Why emojifying issue labels?
Maybe one reason we decided to add emojis in our set of issue labels is simply that we could! You actually only can do that since February the 22d this year! Other reasons include that it’s fun, and that emojis make it easier to differentiate issue labels at a glance. Colours are good, more on that later, but not everyone can differentiate them anyway.
How to update issue label sets in practice?
We updated the issue labels more or less automatically, making the most of GitHub’s APIs and of related R packages! The two actual scripts live here and here. Here, we write up some general lessons, updated to make your life easier since the API evolved a bit since we worked on our labels.
We first got the list of all package repos using the experimental ghrecipes package that interacts with GitHub V4 API and is developped in rOpenSci’s ropenscilabs GitHub organization. ghrecipes::is_package returns TRUE if a repo has DESCRIPTION and NAMESPACE files and R and man folders. Maybe you already have such a list of your repos handy!
repos <- ghrecipes::get_repos("lockedata")
repos <- dplyr::mutate(repos,
name = stringr::str_remove(name,
"lockedata\\/"))
# are packages
repos$is_pkg <- purrr::map_lgl(repos$name,
ghrecipes::is_package_repo,
owner = "lockedata")
repos <- dplyr::filter(repos, is_pkg, !is_fork)Once we had that list, we switched to using GitHub’s V3 API via the gh package developed in RStudio’s r-lib organization.
At the time we updated labels, we couldn’t directly update them but in any case now you can, no need to delete and re-create labels at the risk of losing your labelling (we didn’t loose anything though). Note that in general, when messing with your issue trackers automatically, you should definitely test your code on a single repo first, since your power could, for instance, make you unlabel all issues at once, which would be quite bad!
With the current endpoints here’s what you should do:
Take care of your authentication taking into account your rights over the repos and choosing the scope of the token wisely.
List all labels over the repos. It’d look like this.
gh::gh("GET /repos/:owner/:repo/labels", owner = "lockedata", repo = "optiRum")- After doing that, define what each old label is going to become. When defining our new labels, we used this cheatsheet of emojis for GitHub.
# dput(sort(unique(labels$name)))
new_labels <- tibble::tibble(old = c("bug", "duplicate", "enhancement", "first-timers-only", "good first issue",
"help wanted", "invalid", "question", "up-for-grabs", "wontfix"
),
new = c("bug :bug:",
"duplicate :dancers:",
"enhancement :sparkles:",
"good first issue :hatching_chick:",
"good first issue :hatching_chick:",
"help wanted :raised_hand:",
"wontfix :see_no_evil:",
"question :question:",
"help wanted :raised_hand:",
"wontfix :see_no_evil:"))You’ll also need to choose colours. We first used random colours sampled thanks to
charlatan::ch_hex_color()but also chose to use official Locke Data colours for a few of the labels.Then, using this correspondance table and your favorite functional programming / looping method (
purrrin our case, get started with this slidedeck), use that fantastic endpoint that didn’t exist when we did that (or that we missed?). Here’s how it’d look for a single label, identified by its current name, and repo.
gh::gh("PATCH /repos/:owner/:repo/labels/:current_name",
owner = "ropenscilabs", repo = "ghrecipes",
current_name = "enhancement",
name = "feature :sparkles:",
color = "ffa07a",
description = "stuff that'd be nice to add",
.send_headers = c(Accept = "application/vnd.github.symmetra-preview+json"))Notice that the color has to be a hex code, minus the “#”, and also notice the .send_headers parameter. I’ve tested the above chunk for real and it worked. Depending on the current state of your repos, you might want to create labels from scratch after deleting labels. But updating labels is good because it means that if the labels are already used, the labelled issues won’t loose their labelling.
Now, enjoy labels by working on issues!
Admire the set of issues we can now use in each of our package repos:
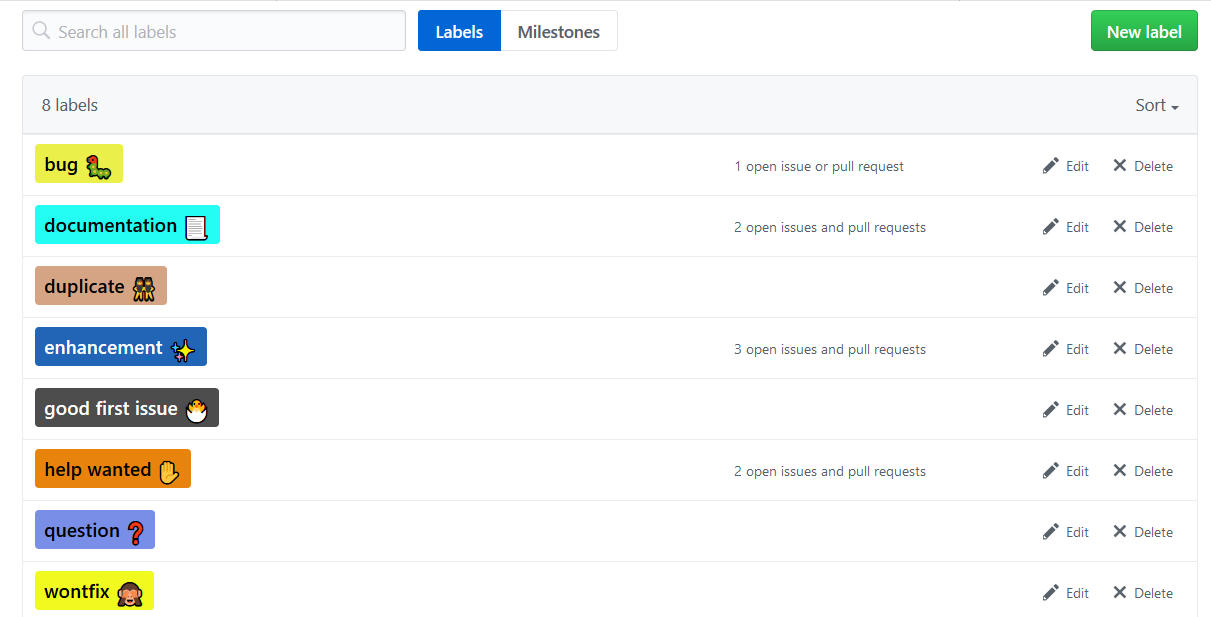
Locke Data issue labels
Here’s for instance the datasauRus issue tracker whose pretty labels inspired Irene Steves.
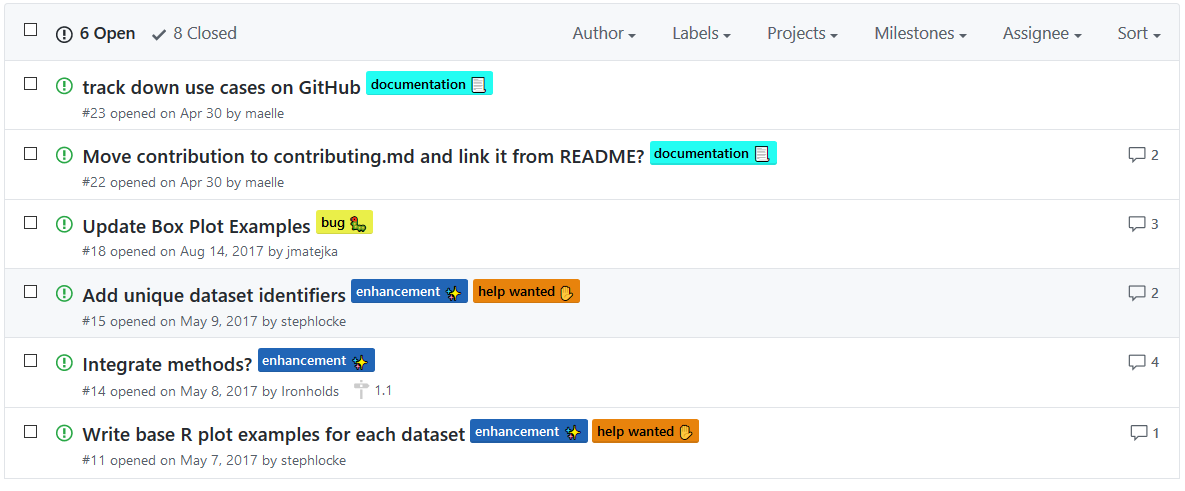
datasauRus issue tracker
Now, it’s time for us to get cracking on some of our repo issue trackers! Have fun with your own labelling!
Edited to add: usethis::use_github_labels might be of interest, although it doesn’t update the names of existing labels. It is probably particularly useful for setup. Also follow this issue thread including a prototype of an issue label set by Mara Averick, with emojis.